Data-set:
- Amazon data-set with:
- ~1 million reviews with more than 10 helpful votes from other Amazon users under Entertainment category
- Split into training and testing sets, 800000 training reviews and 200000 testing reviews
- Cycled through the 800000 training reviews due to such a large number being computationally infeasible to train on all at once for the models I used.
- ~1 million reviews with more than 10 helpful votes from other Amazon users under Entertainment category
Process:
- Used Amazon review data set full of hundreds of thousands of reviews with votes from other users on whether they were helpful or not
- Used skip-gram model and neural network to create word embeddings for vocabulary compiled from many Amazon reviews.
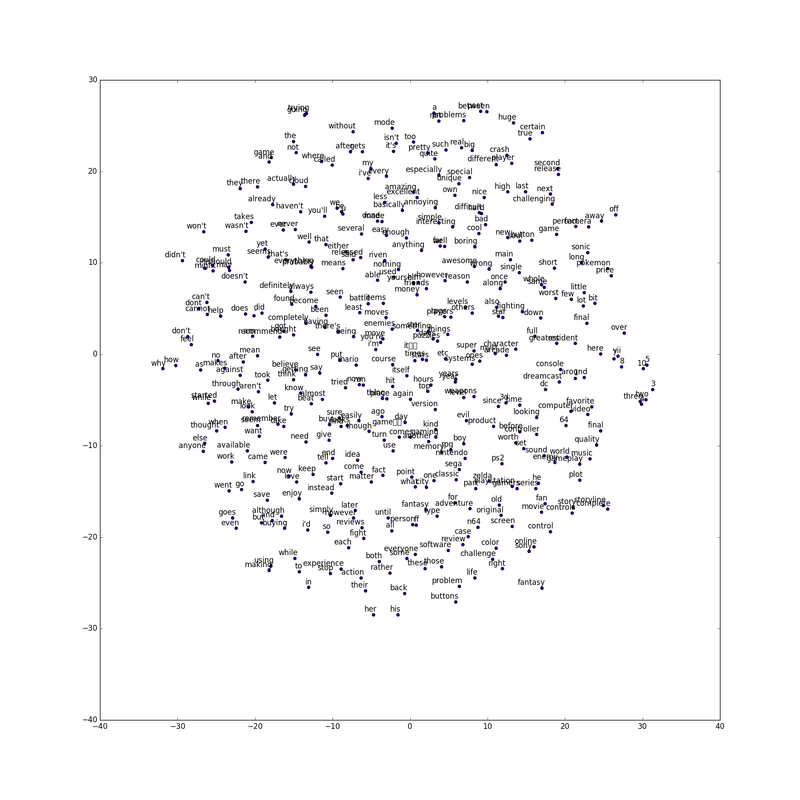
- The figure below shows dimensionally reduced word embeddings for a select number of words in that vocabulary of around 25000 words:
- Clustered the word embeddings using k means algorithm into 100 clusters.
- Used these clusters as classifiers for the word embeddings to reduce them instead of creating smaller dimensional word embeddings to begin with.
- Took each review and used the word embeddings of each word in two ways:
- Created one final review embedding as the sum of every word embedding in the review
- Created bins of final embeddings for large clusters, each bin being the sum of every word embedding from words belonging to that bin's cluster.
- Created one final review embedding as the sum of every word embedding in the review
Results:
- Both methods yielded similar testing accuracy on my test set size of 200000 examples (reviews).
- Accuracy defined as percentage of examples classified as helpful or not correctly when compared to Amazon user votes. If a majority of users voted helpful, the classification was a 1. Otherwise, it was 0.
- kNN tended to achieve ~58% testing accuracy with a high of 58.2%
- Decision tree tended to achieve ~66% testing accuracy with a high of 67.4%
- Neural network tended to achieve ~70% testing accuracy with a high of 71.2%
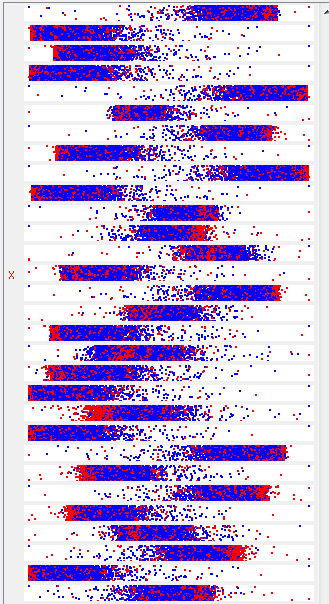
- The following figure shows example classifications (blue for helpful, red for not) that shows that my attributes didn't resolve enough substantial differences between the two classes to prevent my model from over fitting the training set too easily.